dokieli documentation
More details about this document
- Identifier
- https://dokie.li/docs
- Published
- Modified
- Document Type
- Article
- License
- CC BY 4.0
- Language
- English
- Feedback
- Git repository (pull requests, new issue, open issues)
Abstract
dokieli's documentation covers its design principles, architecture, accessibility statements, privacy policy, setup instructions, and usage guidelines that can be useful to authors and developers.
Principles
Dokieli is a client-side editor and browser extension for decentralised article publishing, annotations, and social interactions, built as an open-source project using open web standards. Dokieli's core design principles are autonomy and universal access.
As an application running in the web browser, dokieli works independently of any specific server or service. All content produced by dokieli can be used by other standards-compliant applications. dokieli takes a privacy-conscious approach by allowing individuals to choose where they store their content and who can access it. Dokieli does not collect or share its users' data.
Made with fun.
Getting started
Here is how you can use dokieli and get involved:
Using dokieli
Embeddable Web Application
Dokieli can be embedded into any HTML document by including its CSS and JavaScript in the <head> section of the document. Once the document is opened in any browser, dokieli provides authoring, annotating, and publishing features.
<link href="https://dokie.li/media/css/basic.css" media="all" rel="stylesheet" title="Basic" /><link href="https://dokie.li/media/css/dokieli.css" media="all" rel="stylesheet" /><script src="https://dokie.li/scripts/dokieli.js"></script>
Dokieli can also be embedded in an iframe within an existing HTML document or dynamically as a Blob using JavaScript. This enables full editing and annotation features directly inside the frame. For example:
<iframe height="720" src="https://dokie.li/new" width="1280"></iframe>Web Extension
Dokieli can also be used as a browser extension, providing full functionality directly in the browser. The extension works in Firefox and Chromium-based browsers, offering a browser toolbar option that enables the same features as the standalone web application.
Install from your browser's add-on store:
- Firefox
- Firefox Add-ons: dokieli
- Chromium
- Chrome Web Store: dokieli (Chrome, Brave, Vivaldi, and other Chromium-based browsers)
Alternatively, the extension can be loaded manually from source:
- Clone the dokieli repository from https://git.dokie.li/ (or fork it).
-
- Firefox
- From the "Add-ons and themes" menu, select "Debug Add-ons" (or go to
about:debugging#/runtime/this-firefoxfrom the addressbar) and import by selecting any file from the cloned dokieli directory (e.g.,manifest.json). See also temporary installation in Firefox. Note that if you restart your browser, you'll need to go through this process. - Chromium
- The general process for browsers such as Chrome, Brave, Vivaldi, etc., are as follows. From the "Extensions" menu (or go to
chrome://extensions/,brave://extensions,vivaldi://extensions/from addressbar), check the "developer mode" option. Import the dokieli directory from "Load unpacked".
Contributing
Thank you for investing your time in contributing to the dokieli project! All kinds of contributions are welcome - code, ideas, feedback, and more.
The dokieli repository has the source, and there's a contributing guide to get started. Use dokieli. Test it. Report bugs or fix them. Improve docs. Write or translate articles and share them. Add to the examples. Join the chat for help or discussion. Share ideas or open issues for features you want to see. Every bit helps move the project forward.
Illustrations by Patrick Hochstenbach, Creative Commons Attribution 4.0 International.
Roadmap
Here are the features and improvements in dokieli's roadmap. Everything here is subject to change.
Credibility assessment
- Description
- Combat misinformation, improve digital literacy and critical reading skills, trustworthy publishing through tools for content analysis and knowledge extraction, content validation, source evaluation, and fact checking.
- Planned for
- –
- Contribute
- Financial support, code.
Modularization
- Description
- Refactor major parts of dokieli (annotations, notifications, sharing) into standalone npm packages.
- Planned for
- –
- Contribute
- Financial support, code.
End-to-end encryption
- Description
- Add client-side encryption for all shared content.
- Planned for
- –
- Contribute
- Financial support, code.
Mobile support
- Description
- Adapt the interface for smooth use across mobile devices.
- Planned for
- –
- Contribute
- Financial support, code.
Knowledge organisation
- Description
- Support structuring, searching, and linking document content.
- Planned for
- –
- Contribute
- Financial support, code.
Documents
Articles, annotations, and notifications are the main types of documents dokieli generates.
- Article
-

Dokieli supports authoring various kinds of articles, such as blog posts, course descriptions, guides, news articles, recipes, reviews, scholarly articles, slideshows, technical specifications, theses, travelogues, or anything that simply is an "article". Articles are both human- and machine-readable, and can be highly structured, linked, versioned, annotated, shared, access-controlled, and stored across different storages. Collections of articles can be syndicated via web feeds. While annotations and notifications differ in purpose, they share a similar structure and usability.
- Annotation
-
An annotation is a standalone piece of information about, or part of, an article or another annotation, with purposes such as assessing (approve, disapparove), bookmarking, classifying, commenting, describing, linking, replying, questioning, or tagging. Annotations can be stored in locations like personal storage or an annotation service, and each can have its own language, license, and inbox to receive related notifications. When an article or annotation with an inbox is annotated, a notification is automatically sent to enable discovery. Although annotations can be displayed in the context of their targets, they remain distinct resources and are not stored with the article.
- Notification
-
A notification describes an activity such as an annotation, a citation, or a share action, and is sent to a target's inbox, e.g., an article, annotation, person, or group. Notifications are brief and include key provenance details, such as who performed the action, when, where, the motivation, licensing, and language, helping consumers decide whether to engage further. The notification does not include the full content, e.g., an annotation body, but provides links to fetch it. Notifications help surface related activities in context and can support workflows like collaboration, credibility checks, or peer review.
Storage
Articles and annotations can stored in various places such as personal storage, annotation service, or local storage.
- Personal storage
- A personal storage is where individuals or groups can store their personal information, as well as articles, annotations, and notifications. The storage is typically access controlled for reading or writing data.
- Annotation service
- An article or annotation can offer an annotation service in which their responses can be stored. An annotation service may or may not be access controlled. annotation service can also serve as a place for a copy of annotation stored elsewhere.
- Local storage
- The local storage in the user's browser is used for autosave and offline access.
User interface
In this section we go over dokieli's UI; interface modes, menu, and features.
Modes
The user interface (UI) can be in either social or author. The modes can be switched from the dokieli menu via the Edit operation.
- Social
- The social mode focuses on features allowing users to view, annotate and share content. This is the default mode when the document loads without specific directives.
- Author
- The author mode focuses on features allowing users to edit and publish the article. It enables editing of content, structure, and semantic annotations.
Features
dokieli's features make it possible to view, create, and share content.
- UI Language
- The UI language can be changed based on avaiable translations. This feature is separate from content language settings for the article and annotations.
- Sign in
- The sign in enables the user to identify themselves with dokieli using their personal online identifier. dokieli gathers the information linked from the user's profile to adapt the user interface and to customise interactions based on their preferences.
- WebID
-
- What is WebID?
- A WebID is your unique digital identity on the decentralised web. Unlike traditional accounts, you own and control your WebID and the personal data and profile information associated with it.
- Why use it?
- It allows you to log into any compatible app without sharing personal data. Your data stays in your personal data store, not on the app's servers.
- Where to get an account?
- Solid Community Community maintained free storage and WebID.
- Once you have a WebID, it usually looks like a URL. For example:
https://username.solidcommunity.net/profile/card#me
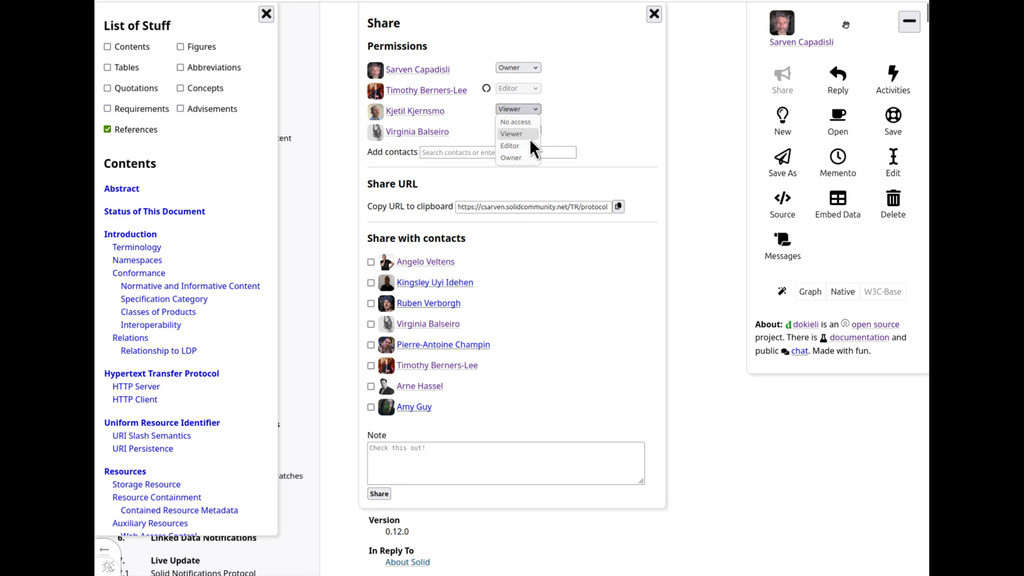
- Share
-
Share makes it possible to notify specific individuals and groups about an article or a specific part within. Signed in users having owner permissions on an article can give others the permission to view, edit, or be co-owners. The contacts listed are the ones discovered through signed in user's profile that have the means to receive notifications in their inboxes. The notification includes minimal information about the article, such as who sent the notification, when it was created, its license and motivation.
Video (poster) of dokieli Share [, WebM] - Reply
- An article can be replied with a note and have its own language and license. The user can specify where they want to save their reply by browsing to a location in a personal storage or an annotation service.
- Notifications
-
The Notifications feature helps to view your own and your own contacts' interactions and activities on documents, such as comments, annotations, reactions, and bookmarks. Sign in to dokieli so that it can find these notifications.
Video (poster) of notifications in dokieli [, WebM] - Bookmarking
- The document or selected text can be bookmarked where the user can include a note, assign tags.
- Commenting
- Node or text level targeting for an annotation including a description and tags.
- Describing
- A note to indicate a footnote. Used as part of purpose for bookmarking and commenting.
- Highlighting
- Node or text level targeting that gives the user a URI that they can use for deep-linking and referencing.
- Tagging
- The user can associate tags (natural language text) to selected text which is used as part of purpose for annotations such as bookmarking, replying, and commenting.
- Approve
- General agreement with the selected text. Optional note can indicate why the selection is a strong point or a convincing argument.
- Disapprove
- General disagreement with the selected text. Optional note can indicate why the selection is a weak point, an error, or inaccurate.
- Specificity
- Request to increase specificity on selected text. Optional note can indicate that a citation or more specificity is needed.
- New
-
A new document can be temporarily authored until it is stored in personal storage or local storage. In order to persist the article long term, the user can Save or Save as the article. New documents can be created from temmplates such as:
- Article
- An article, such as a blog post, story, or report.
- Slideshow
- A presentation of a series of slides.
- Curriculum Vitae
- An academic and professional history and achievements.
- Open
-
A document can be opened (imported) from a local filesystem or by specifying the URL of the resource on the web. resource browser can be used to navigate to the document of interest in the personal storage or annotation service. Custom views are available when importing some data formats such as:
- HTML documents
- When opening an (X)HTML document, only the content is imported. CSS, JavaScript, and other additional elements are excluded for security reasons. After importing, dokieli can be used as usual with all of its features.
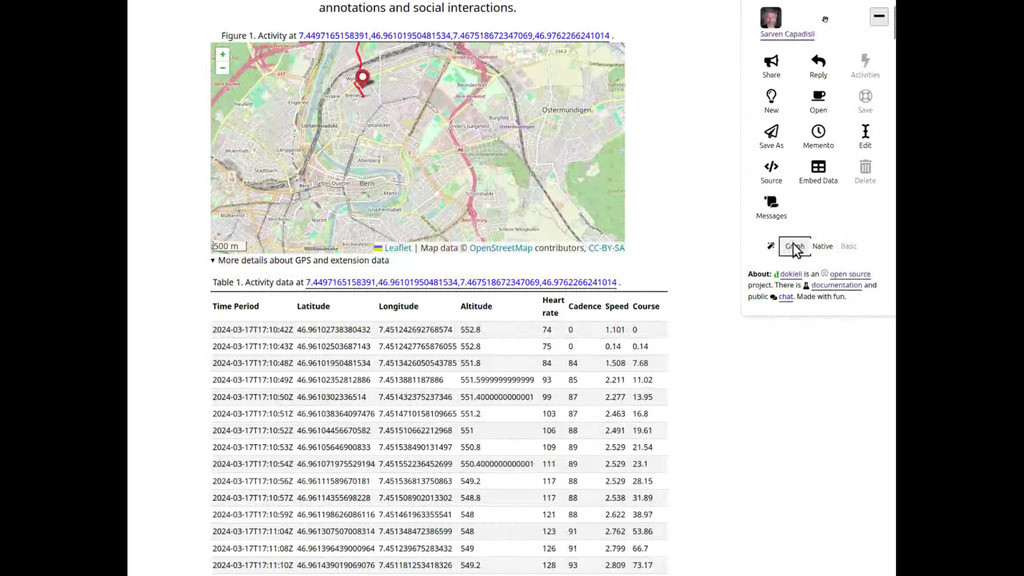
- Geo and Stats
-
The user can view a map (OpenStreetMap) that includes a track, along with detailed GPS and extension data in a table. This data includes time period, latitude, longitude, altitude, heart rate, cadence, speed, air temperature, water temperature, and depth. The table also provides a summary of the publication date, publisher, actor, total distance, total time, average pace, average heart rate, elevation gain, and elevation loss. Additionally, the nearest city to the track is identified and linked on Wikidata.
Video (poster) of Geo and statistical data importing and viewing in dokieli [, WebM] - Activity collection
- The user can view a chronological list of social interactions and content-related activities, such as posting, liking, following, and sharing, within a collection.
- Other data
- Data in unsupported or unrecognized formats will be displayed as-is, without any processing.
- Save
- An article can be saved in its current state and location, making it possible to return to the same content and URL later, when access is available.
- Save As
-
An article can be saved in its current state at a specific location in a personal storage. This feature uses the resource browser to navigate HTTP URLs.
- Set inbox
- An inbox can be assigned to an article or annotation by specifying its location using the resource browser so that notifications about the article or annotation can be shared.
- Set annotation
- An annotation service can be assigned to an article or annotation by specifying its location using the resource browser so that others' annotations can optionally be copied to this location.
- dokielize
- Normalises the document to be valid, normalised, as well as includes the dokieli scripts so that the application be used in the derived version.
- Derivation data
- When derivation data is checked for inclusion, derived from and on information is included in the created document.
- Accessibility report
- Provides additional accessibility information about the current document so that the author can find ways to improve the content's accessibility.
- Storage details
-
The user can examine information about the storage such as its location, name, description, owners, URI persistence policy, and digital rights policies as well as be informed about any conflicts with their preferred policies, and notification subscription options and subscribing to live changes.
Video (poster) of ODRL in dokieli [, WebM]
- Version
- Generates a derived copy of the current document as a mutable resource including provenance.
- Immutable
- Generates a derived copy of the current document as an immutable or frozen Memento resource including provenance. Creates or updates a Memento TimeMap including a reference to the immutable resource.
- Memento
- The user can access the memento (version history) of a document.
- Robustify Links
-
To help mitigate content drift and link rot, links can be enhanced with additional context such as a snapshot URI from the Internet Archive, a timestamp of when the link was created, and other relevant metadata.
Video (poster) of robustify links in dokieli [, WebM] - Archive
- Sends an archival request of the current article to the Internet Archive Wayback Machine.
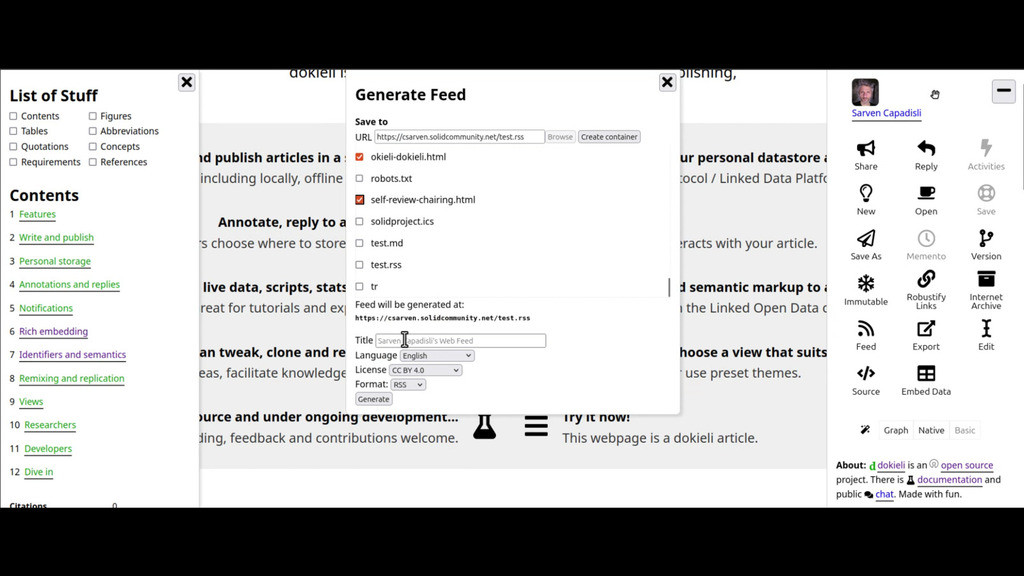
- Generate Feed
-
Enables the creation and publication of a custom web feed from a selected list of documents in personal storage, with options to set the feed's title, language, license, and format, e.g., RSS or Atom.
Video (poster) of generating and publishing web feed in dokieli [, WebM] - Export
- The user can export the article as HTML and save to their local filesystem.
- Triggers the browser to print the current document.
- Edit
-
The Edit feature offers authoring tools for formatting, linking, and structuring articles. Edits are local unless autosave is enabled or changes are committed using Save, Save As, Version, or Immutable. Standard formatting options include headings, italics, bold, ordered and unordered lists, inline code, preformatted text, hyperlinks, inline quotes, images, and tables. Additional capabilities include:
- Collaborative editing
-
The collaborative editing feature enables real-time multi-user document editing. When available on a supporting server, multiple people can edit the same document simultaneously, with each participant's cursor and presence visible to others. Try it at https://dokie.li/demo.
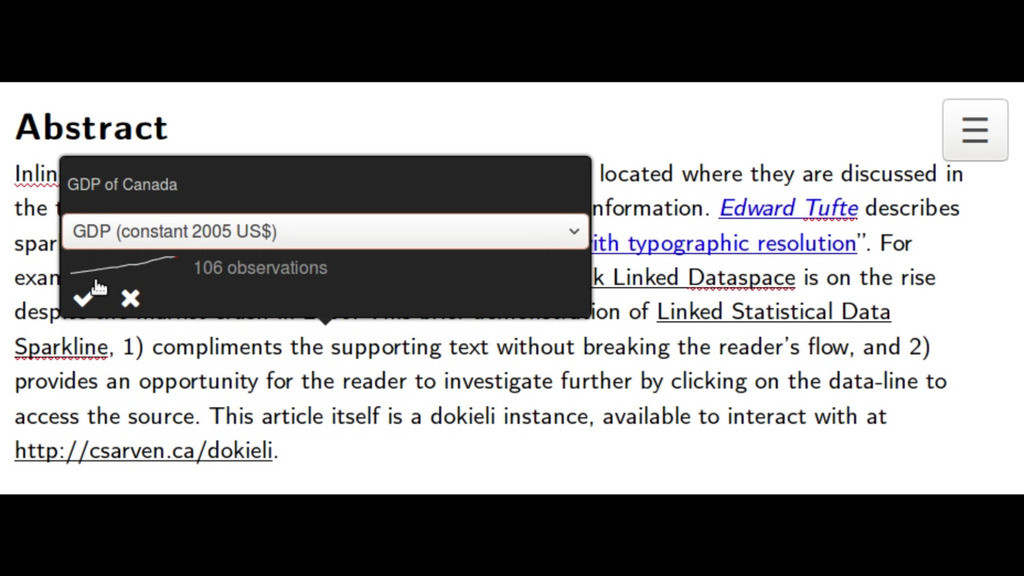
- Interactive and embeddable objects
-
Charts and other visual elements, such as sparklines, can be embedded based on statistical data.
Video (poster) of Sparqlines interaction in dokieli [, WebM] - Semantic annotation
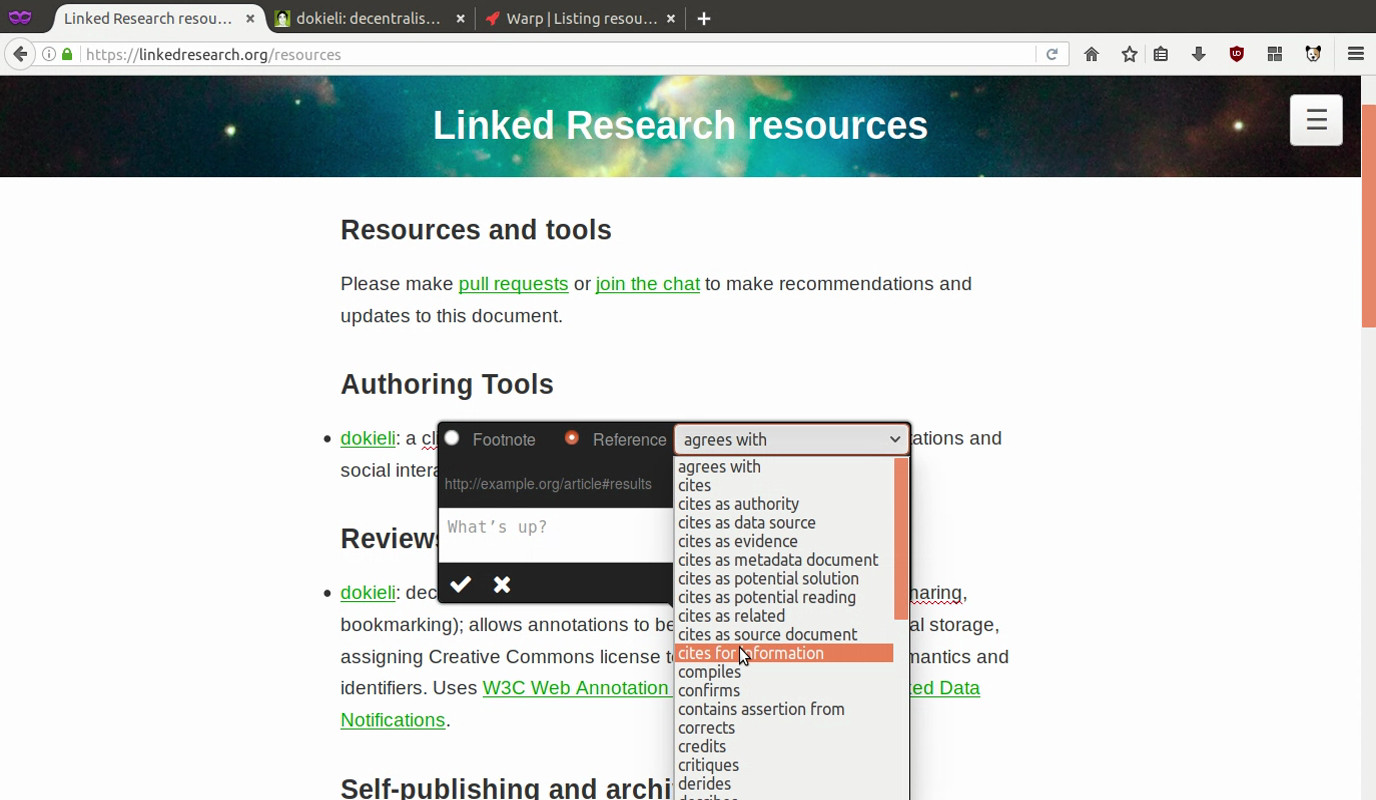
- Content can be semantically marked to enhance machine-readability (RDFa), while remaining human-readable.
- Footnotes and citations
-
Footnotes and citations can be added to selected text, providing contextual, robust references. Cited entities can be notified for back-referencing. References may include ISBNs or URLs. For contextual citations, for example, a citing entity (an argument) may reference a cited entity (observation results) as factual evidence. Bibliographic searches for technical specifications are also supported for citation purposes.
Video (poster) of semantic inline citations and notification in dokieli [, WebM] - Authoring widgets
- Additional authoring options include adding contributors and notifying them, setting the document's language, license, inbox, in reply to, status, type, and test suite.
- Autosaving
- While the user is editing their article, the document is autosaved to local storage. When the autosave toggle is enabled, changes are synchronised with the remote resource.
- Source
- Allows direct editing of the article's current state. Updating is temporary until committed using features such as changes are committed using Save, Save As, Version, or Immutable.
- Embed Data
- Enables embedding and updating supplemental data to be stored with the article using RDF syntaxes such as Turtle, JSON-LD, and TriG.
- Message Log
- Displays all messages raised by dokieli, for example as feedback or notifications resulting from specific actions.
- Delete
- Deletes article or annotation from personal storage, when access is available.
- Views
- The dokieli menu lists primary and alternate stylesheets that are detected in the HTML. Native is always available and disables all other stylesheets, allowing the user agent’s default styles to apply. When a view is selected—e.g., Basic (which is the current primary stylesheet for this article)—it becomes the primary stylesheet, while the others are set as alternate and disabled.
- Graph view
- Displays a graph visualisation of the document's underlying semantics, including a list of resources, the number of statements, unique nodes, creator, license, and a legend. The visualisation can be exported as an SVG.
- Review changes
- The review changes feature allows comparing local and remote versions of a document when both have changed, and choose to keep the local edits, discard them in favour of the remote version, or manually reconcile and apply changes to both.
- List of Stuff
-
Options to generate and include various types of content, such as:
- Contents
- Generates a table of contents.
- Figures
- Lists all figures in the document with links to each.
- Tables
- Lists all tables in the document with links to each.
- Abbreviations
- Lists abbreviations in the document along with their definitions.
- Quotations
- Lists all quotations in the document with links to each.
- Concepts
- Lists concept schemes and concepts in the document with links. Additional concepts from externally referenced resources can also be included, along with a graph visualisation of the concepts.
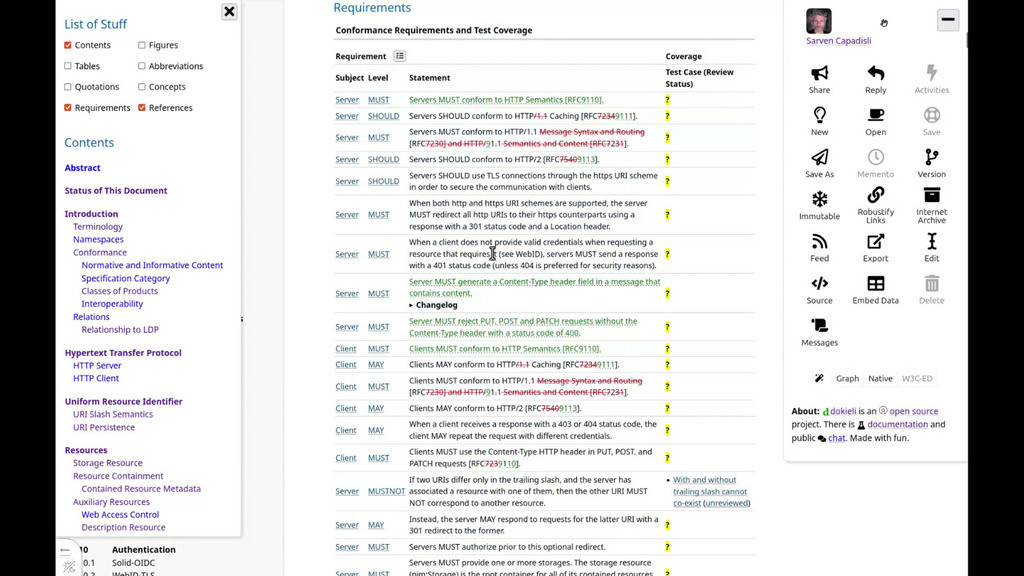
- Requirements
-
Creates a table of conformance requirements and test coverage (for technical specifications), showing the requirement subject, level, statement, and related test cases with links. Optionally displays changes between the current and previous versions of the document, along with changelog details.
Video (poster) of in dokieli [, WebM] - Advisements
- Creates a table of advisements (in technical specifications), including their levels, statements, and links.
- References
- Lists references in the document with links to each.
- Document metadata
- Based on document's underlying structured data, displays information about its contributors such as editors and authors, number of citations, requirements, advisements, concepts, statements, as well as an estimated reading time, number of characters, words, and bytes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Components
Articles, annotations, and notifications can include common components that provide additional information or functionality.
- License
- Licenses and rights can be specified for articles and annotations from a list of Creative Commons options, e.g., CC BY 4.0. Notifications, by default, use the CC0 1.0 Universal license.
- Language
- The language of an article or annotation can be set from a list (182 languages available, e.g., Armenian). Alternatively, language can be applied to specific text selections or nodes using the semantic annotator.
- In reply to
- Identifies a resource to which the current resource is a reply.
- Resource browser
- The resource browser is part of features such as New, Open, Save As, and Generate Feed lets you navigate locations such as a personal storage, annotation service, or a activity collection. If a personal storage location is known, it is used by default; otherwise, the start location can be based on an annotation service referenced by the article.
- Base URL selection
- When creating or saving documents, media resources (e.g., head link, [src], object[data]) are normalised to use the document's base URL as their absolute path (the
Use references as is
option). IfCopy to your storage
is selected, relative URLs remain unchanged, as the copy process reuses the same file paths. - Clipboard
- Text, code, and tables (in CSV format) can be copied to the clipboard.
- Fragments
- Clickable fragments are available for easy, specific referencing within the document.
- Tabs view
- Navigation items are presented in a tabbed view for easier access.
Accessibility, Usability, and Inclusion
Accessibility Statement
Measures to support accessibility
dokieli takes the following measures to ensure accessibility of dokieli:
- Include accessibility throughout our internal policies.
- Assign clear accessibility goals and responsibilities.
- Employ formal accessibility quality assurance methods.
Conformance status
The Web Content Accessibility Guidelines (WCAG) defines requirements for designers and developers to improve accessibility for people with disabilities. It defines three levels of conformance: Level A, Level AA, and Level AAA. dokieli is partially conformant with WCAG 2.1 level AA. Partially conformant means that some parts of the content do not fully conform to the accessibility standard.
Feedback
We welcome your feedback on the accessibility of dokieli. Please let us know if you encounter accessibility barriers on dokieli issues.
Technical specifications
Accessibility of dokieli relies on the following technologies to work with the particular combination of web browser and any assistive technologies or plugins installed on your computer:
- HTML
These technologies are relied upon for conformance with the accessibility standards used.
Assessment approach
dokieli assessed the accessibility of dokieli by the following approaches:
- Self-evaluation
Privacy Policy
Application Privacy
dokieli is a client side application, and can be hosted from any web server. It does not collect, transmit, or store any data about its users on remote servers. No analytics, telemetry, or tracking is built into the application. All content produced using dokieli is directed entirely by the user to destinations of the user's own choosing.
dokie.li website policy
The dokie.li website is a simple static server. When the application's assets (HTML, CSS, JavaScript) are served from dokie.li, the server receives and logs standard HTTP requests, as is the case with any web server. Those logs are not processed for analytics, profiling, or any other purpose beyond routine server operation. When dokieli is deployed elsewhere, the dokie.li server is not involved in serving the application. In-app help (the info buttons), however, fetches documentation from https://dokie.li/docs by default, or from another origin if the deployer configures one. These are ordinary cross-origin browser requests and disclose nothing beyond what the browser already sends, including the origin of the deploying site to the docs origin.
Outbound requests
dokieli makes outbound requests to resources and services as directed by the user. Those requests originate directly from the user's browser, which discloses the user's IP address to the destination server. This is a standard characteristic of web browsing, not something specific to dokieli. It applies when fetching documents, annotations, profiles, or other linked data, as well as when sending notifications or signing in via a WebID provider. Users can configure a preferred proxy if they wish to limit IP disclosure to external servers.
Local storage
dokieli uses the browser's local storage for autosave and offline access. When signed in, a refresh token is also stored to keep the session active without requiring repeated sign-ins. On a shared device, content and credentials held in local storage may be visible to others using the same browser profile. Signing out clears authentication credentials and session data, including any stored tokens, from local storage. In private or guest browsing mode, local storage is cleared automatically when the session ends. Users on shared devices should sign out when finished, or use private browsing mode, to ensure any remaining content is also removed. A UI language preference may be retained in browser storage between sessions as a convenience. It contains no identifying information and is not linked to any account or profile.
Service worker
dokieli uses a service worker to cache the application's own assets for offline use. The service worker does not store any user data, content, or identifying information, and does not perform any tracking.
Third-party services
Some features make outbound requests to third-party services. This includes resources embedded or referenced in documents and annotations by their authors, which may trigger requests to external servers when that content is loaded. It also covers dedicated features. The archiving feature, for example, sends a snapshot request to the Internet Archive's Wayback Machine, which involves the URL being archived and the user's IP address. When using such features the user is interacting directly with the relevant third party and that service's own policies apply. Protected resources are exempt from public archiving since the request to create an archive snapshot does not carry credentials.
Privacy contact
For privacy-related questions or concerns, please open an issue in the issue tracker at https://git.dokie.li/.